今日值得关注的大模型前沿论文
华为科学智能体 Agent K v1.0已达 Kaggle 大师水平
Meta 团队提出自一致性偏好优化 ScPO
微软、国科大提出 BitNet a4.8:4 位激活的 1 位 LLM
DynaMem:用于开放世界移动操纵的在线动态空间语义记忆
谷歌新研究:由视频生成带有相机轨迹的新视频
TIP-I2V:用于图生视频的百万真实文本、图像提示数据集
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看“2024必读大模型论文”
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
华为科学智能体 Agent K v1.0已达 Kaggle 大师水平
在这项工作中,来自华为诺亚方舟实验室和伦敦大学学院的研究团队提出了 Agent K v1.0,它是一个端到端自主数据科学智能体(agent),旨在对各种数据科学任务进行自动化、优化和泛化。
通过从经验中学习,Agent K v1.0 可以完全自动化地管理整个数据科学生命周期。它利用高度灵活的结构化推理框架,在嵌套结构中动态处理记忆,有效地从积累的经验中学习,从而处理复杂的推理任务。它通过有选择地存储和检索关键信息来优化长期和短期记忆,并根据环境回报来指导未来决策。这种迭代方法允许它在不进行微调或反向传播的情况下完善决策,通过经验学习实现持续改进。
以 Kaggle 竞赛为案例,他们对 agent 的能力进行了评估。按照全自动协议,Agent K v1.0 系统地处理复杂的多模态数据科学任务,采用贝叶斯优化法进行超参数调整和特征工程。
他们利用新评估框架严格评估了 Agent K v1.0 的端到端功能,即从 Kaggle 竞赛 URL 开始生成和发送提交的功能。结果表明,Agent K v1.0 在表格、计算机视觉、NLP 和多模态领域的各项任务中取得了 92.5% 的成功率。通过计算每个人的 Elo-MMR 分数,在与 5856 名 Kaggle 人类竞争对手进行基准比较时,Agent K v1.0 排名前 38%,显示出与专家级用户相当的整体技能水平。值得注意的是,它的 Elo-MMR 分数介于人类特级大师分数的第一和第三四分位数之间。此外,结果表明,Agent K v1.0 的性能已达到相当于 Kaggle 大师的水平,根据 Kaggle 的晋级系统,它已获得 6 枚金牌、3 枚银牌和 7 枚铜牌。
论文链接:
https://arxiv.org/abs/2411.03562
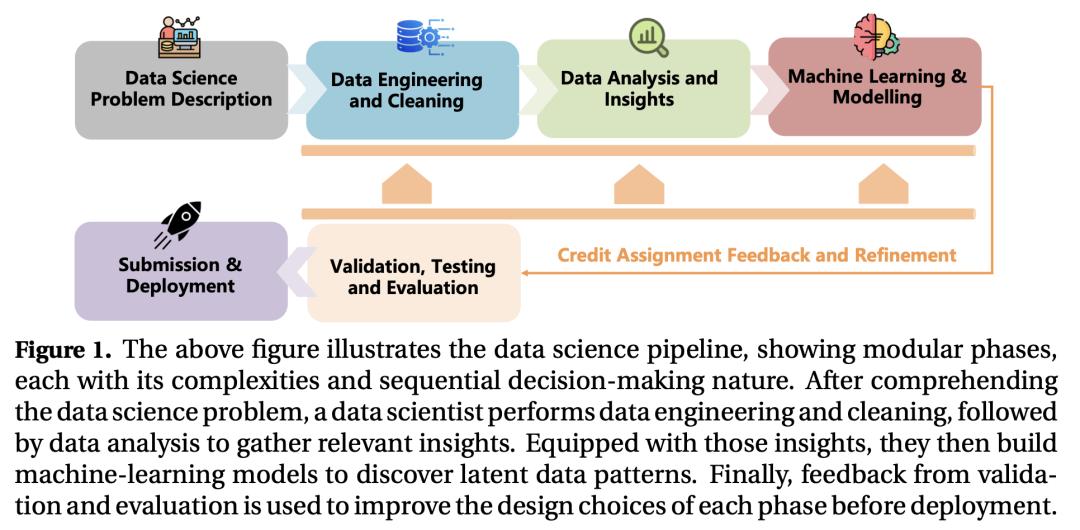
Meta 团队提出自一致性偏好优化 ScPO
自对齐(Self-alignment),即模型在没有人类标注的情况下学会自我改进,是一个发展迅速的研究领域。然而,由于难以分配正确的奖励,现有技术往往无法改进复杂的推理任务。
众所周知,自一致性(self-consistency)是一种能提高正确性的正交方法,它是一种在推理时应用的基于多重采样的方法,目的是找到最一致的答案。在这项工作中,来自 Meta 和北卡罗来纳大学教堂山分校的研究团队扩展了“自一致性”的概念,他们提出了自一致性偏好优化(ScPO),在无监督的新问题上反复训练一致性答案,使其优先于不一致性答案。
研究表明,在 GSM8K 和 MATH 等推理任务上,ScPO 比传统的奖励模型训练有很大改进,缩小了与使用 gold answers 或偏好进行监督训练的差距。在 ZebraLogic 上,ScPO 将 Llama-3 8B 优化为优于 Llama-3 70B、Gemma-2 27B 和 Claude-3 Haiku。
论文链接:
https://arxiv.org/abs/2411.04109
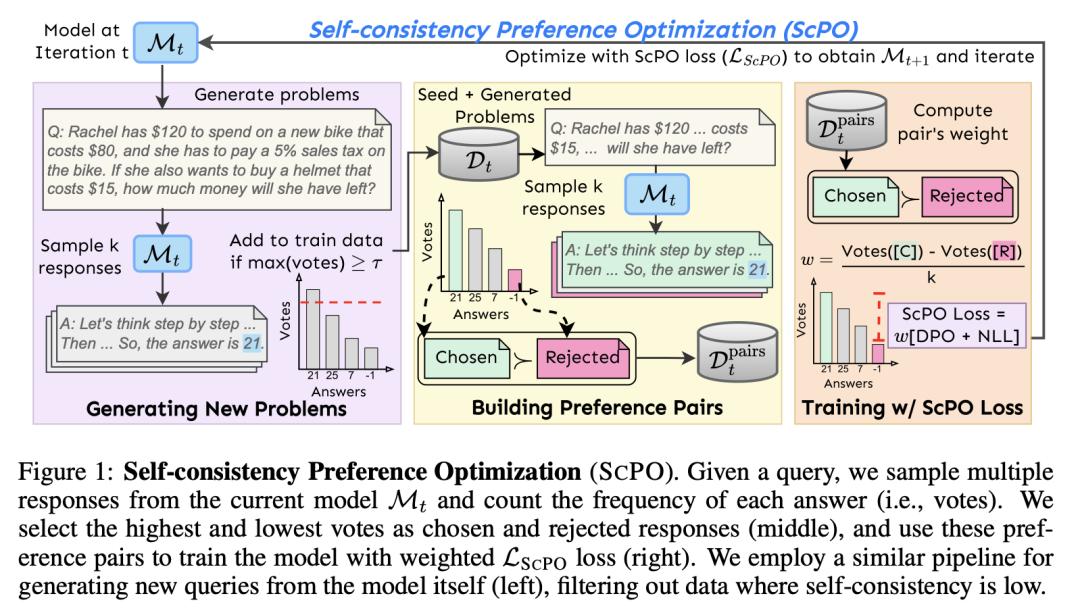
微软、国科大提出 BitNet a4.8:4 位激活的 1 位 LLM
最近对 BitNet b1.58 等 1 位大语言模型(LLM)的研究,为降低 LLM 的推理成本并维持性能提供了一个很有前景的方向。
在这项工作中,来自微软研究院和中国科学院大学的研究团队提出了 BitNet a4.8,使 1 位 LLM 可以实现 4 位激活。BitNet a4.8 采用混合量化和稀疏化策略,以减少离群通道带来的量化误差。具体来说,他们对注意力和前馈网络层的输入采用 4 位激活,同时对中间状态进行 8 位量化稀疏化。
大量实验证明,BitNet a4.8 在训练成本相当的情况下,性能可与 BitNet b1.58 媲美,而在使用 4 位(INT4/FP4)内核进行推理时速度更快。此外,BitNet a4.8 只需激活 55% 的参数,并支持 3 位 KV 缓存,进一步提高了大规模 LLM 部署和推理的效率。
论文链接:
https://arxiv.org/abs/2411.04965
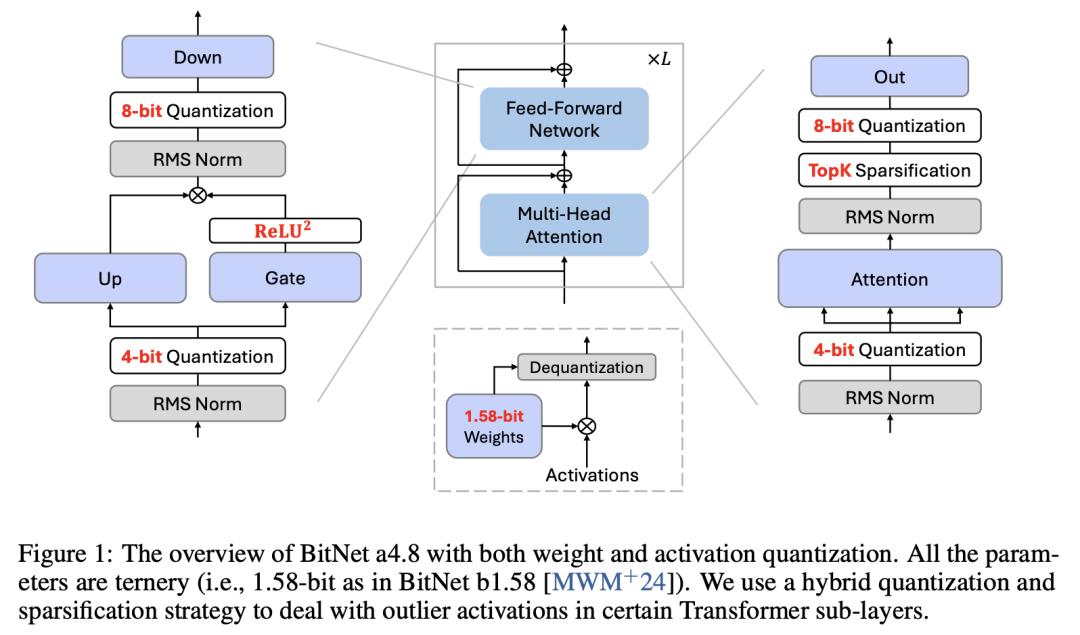
DynaMem:用于开放世界移动操纵的在线动态空间语义记忆
开放式词汇移动操控技术已经取得了重大进展,其目标是让机器人在任何环境中都能根据自然语言描述执行任务。然而,目前的大多数系统都假设环境是静态的,这就限制了系统在现实世界中的适用性,因为在现实世界中,环境经常会因为人类的干预或机器人自身的行动而发生变化。
在这项工作中,来自纽约大学和 Hello Robot 的研究团队提出了一种新的开放世界移动操控方法 DynaMem,其使用动态空间语义记忆来表示机器人的环境。DynaMem 构建了一个三维数据结构来维护点云的动态存储器,并使用多模态 LLM 或由 SOTA 视觉语言模型生成的开放词汇特征来回答开放词汇对象定位查询。在 DynaMem 的支持下,机器人可以探索新环境,搜索内存中没有的物体,并在物体移动、出现或消失在场景中时不断更新内存。
他们使用 Stretch SE3 机器人在三个真实场景和九个离线场景中进行了大量实验,在非静态物体上的平均拾取和投放成功率达到 70%,比 SOTA 静态系统提高了两倍多。
论文链接:
https://arxiv.org/abs/2411.04999
项目地址:
https://dynamem.github.io/
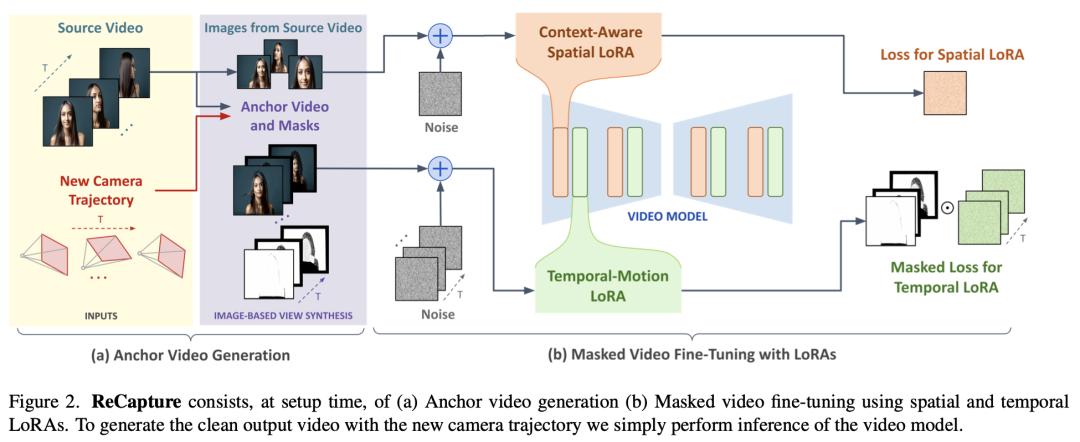
谷歌新研究:由视频生成带有相机轨迹的新视频
最近,视频建模技术取得了突破性进展,可以在生成的视频中控制相机轨迹。然而,这些方法不能直接应用于用户提供的视频,因为这些视频不是由视频模型生成的。
在这项研究中,来自谷歌和新加坡国立大学的研究团队提出了 ReCapture,这是一种从单个用户提供的视频中生成带有新颖相机轨迹的新视频的方法。通过这一方法,他们可以从不同的角度,以电影镜头的运动方式,重新生成包含所有现有场景运动的参考视频。
值得注意的是,使用这一方法,他们还可以生成参考视频中无法观察到的场景部分。他们的方法是:(1)使用多视角扩散模型或基于深度的点云渲染技术,用新的相机轨迹生成有噪声的锚视频,然后(2)使用遮蔽视频微调技术,将锚视频重新生成干净且时间上一致的重新纠缠视频。
论文链接:
https://arxiv.org/abs/2411.05003
项目地址:
https://generative-video-camera-controls.github.io/
TIP-I2V:用于图生视频的百万真实文本、图像提示数据集
视频生成模型正在彻底改变内容创作,其中图生视频模型因其更强的可控性、视觉一致性和实际应用而日益受到关注。然而,尽管这些模型很受欢迎,但它们依赖于用户提供的文本和图像提示,目前还没有专门用于研究这些提示的数据集。
在这项研究中,来自悉尼科技大学和浙江大学的研究团队提出了首个专门用于图像到视频生成的大规模数据集——TIP-I2V,其包含 170 多万个由用户提供的独特文本和图像提示。此外,他们还提供了由五种 SOTA 图生视频模型生成的相应视频。
首先,他们概述了这一大规模数据集的耗时耗资过程。接下来,他们将 TIP-I2V 与两个流行的 prompt 数据集 VidProM(文本到视频)和 DiffusionDB(文本到图像)进行比较,突出基本信息和语义信息的差异。该数据集有助于推进图生视频的研究。例如,为了开发出更好的模型,研究人员可以利用 TIP-I2V 中的提示来分析用户偏好,并评估其训练模型的多维性能;为了提高模型的安全性,研究人员可以重点解决图像视频模型引起的误报问题。
论文链接:
https://arxiv.org/abs/2411.04709
项目地址:
https://tip-i2v.github.io/整理:李雯靖



